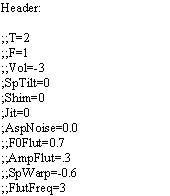MBROLA – Voice Quality Extentions
Internal Report
Department of Phonetics and Dialectology, ISTC-CNR
Institute of Cognitive Sciences and Technology
Italian National Research Council
Via Anghinoni, 10
35121 Padova - ITALY
Staff:
Piero Cosi
cosi@pd.istc.cnr.it
Carlo Drioli drioli@pd.istc.cnr.it
Fabio Tesser tesser@pd.istc.cnr.it
Graziano Tisato tisato@pd.istc.cnr.it
Contact:
Carlo Drioli
Motivations
The necessity of voice quality control in the MBROLA diphone concatenation synthesis is motivated by the recent studies and experimentations on emotive speech synthesis. It is widely accepted, in fact, that voice quality has a relevant role in the transmission of emotions through speech. Previous attempts to model voice quality in the concatenation synthesis framework have been based on recording separate diphone databases for different levels of vocal efforts or voice qualities. However, memory occupation, complex voice design procedure, and range of the voice quality variety limited to the recorded material, are serious drawbacks. On our side, we faced this task by allowing the online processing of the diphones as an intermediate step of the concatenation procedure (see Fig. 1). This step has been implemented using both spectral processing based on DFT and Inverse-DFT transforms, and time-domain processing for pitch-related effects.
Vol SpTilt Shim AmpFlut Jit F0Flut ![]()
AspN
SpWarp![]()
![]()
![]()
![]()
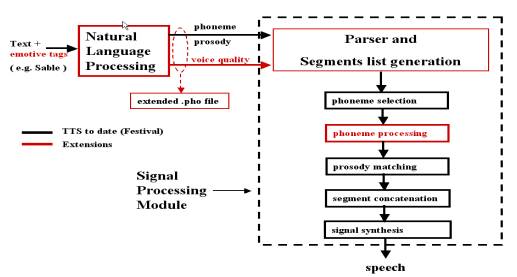
Fig.
1: Extensions to the voice synthesis engine (the Mbrola diphone concatenation
synthesizer).
Implementation
The
MBROLA speech synthesizer, which originally provides controls for pitch and
phoneme duration, has been extended to allow for control of a set of low-level
acoustic parameters that can be combined to produce the desired voice quality
effects. Time evolution of the parameters can be controlled over the single
phoneme by instantaneous control curves. The extended set includes gain
("Vol"), spectral tilt ("SpTilt"), shimmer
("Shim"), jitter ("Jit"), aspiration noise
("AspN"), F0 flutter ("F0Flut"), amplitude flutter
("AmpFlut"), spectral warping ("SpWarp"). Studies on how
these low-level effects combine to obtain the principal non-modal phonation
types encountered in emotive speech are in progress. Here we give a rough
description on how these low-level acoustic controls were implemented:
- Gain
("Vol", range: [-60,+10]): gain control is obtained by simply rescaling of
the spectrum modulus.
-
Spectral tilt ("SpTilt", range: [-1,1]):the spectral balance is changed by a reshaping
function in the frequency-domain that enhances or attenuates the low- and mid-
frequency regions, thus changing the overall spectral tilt.
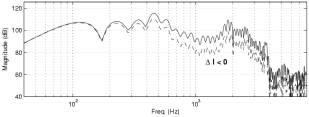
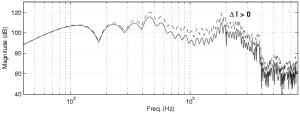
Fig. 2: Action of the spectral tilt
effect (left: SpTilt>0; right: SpTilt<0).
- Shimmer
("Shim", range: [0,1]): this is the difference between the
amplitudes of consecutive periods. It is reproduced by introducing random
amplitude modulations to each consecutive periods of the voiced part of
phonemes.
- Jitter
("Jit", range: [0,1]): this is the period length difference
between consecutive periods. It is reproduced by summing random pitch
deviations to the pitch control curves computed by Mbrola's prosody matching
module (See Fig. 5.1).
-
Aspiration noise ("AspN" , range: [0,1]): for voiced frames, aspiration noise is
generated from the frame DFT transform, by inverse transformation of a
high-pass filtered version of the spectral magnitude, and of a random spectrum
phase.
- F0
flutter ("F0Flut", range: [0,1]): random low frequency
fluctuations of the pitch are reproduced as for Jitter. The low frequency
fluctuations are obtained by random noise band-pass filtering.
- Amplitude
flutter ("AmpFlut", range: [0,1]): random low amplitude fluctuations
are obtained as for Shimmer. The low frequency fluctuations are obtained by
random noise band-pass filtering.
- Spectral
warping ("SpWarp", range: [-1,1]): the rising or lowering of
upper formants is obtained by warping the frequency axis of the spectrum
(through a bilinear transformation), and by interpolation of the resulting
spectrum magnitude with respect to the DFT frequency bins.
- Flutter
frequency ("FlutFreq", range: [3.0,50.0]): speed of the amplitude
and frequency fluctuations. It tunes the second order band-pass filter used by F0Flut
and AmpFlut.
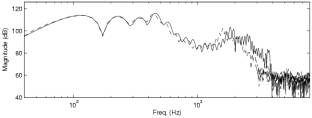
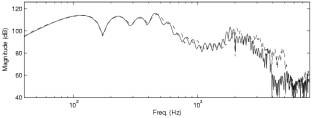 Fig. 3: Action of the spectral
warping effect (left: SpWarp<0; right: SpWarp>0).
Fig. 3: Action of the spectral
warping effect (left: SpWarp<0; right: SpWarp>0).
The Mbrola parser has been modified in order to allow the use of the low-level acoustic controls as general commands or as curves specified at the phoneme level (see the example of an extended .pho file in Fig. 4).

Fig. 4: Example of an extended .pho file. The spectral warping command affects
all phonemes with constant value 0.3, whereas different gain, shimmer and jitter control curves are
specified for different phonemes.
Use –
rules to write the extended .pho files
If voice quality control is
exploited only through commands in the header section of the .pho file, just
add a ;;<ControlName = value> line in the header section. ControlName
must be one of Vol, SpTilt, Shim, Jit, AspN, F0Flut, AmpFlut, SpWarp, FlutFreq,
and value should be within the range corresponding to the control type.
If voice quality control is
exploited through phoneme-specific commands, then the following rules must be
followed:
1. A command is appended to the right of the phoneme by specifying the command type and the time trajectory using the same convention used for the pitch (see Fig. 4).
2. When appending commands to the right of the phoneme, the following order
must be followed: Vol, SpTilt, Shim, Jit, AspN, F0Flut, AmpFlut, SpWarp, FlutFreq.
Note that not all commands need to be specified, e.g. Jit can be used after Vol
(bun not after AspN).
3. When a command is appended to the right of a phoneme, the time trajectory
specification must always begin with the 0% instant, and terminate with the
100% instant.
Examples
Experiments
on the reproduction of typical non-modal phonation modalities (in Italian)

A French
example: